AI eval verifier gets structured output and retry logic
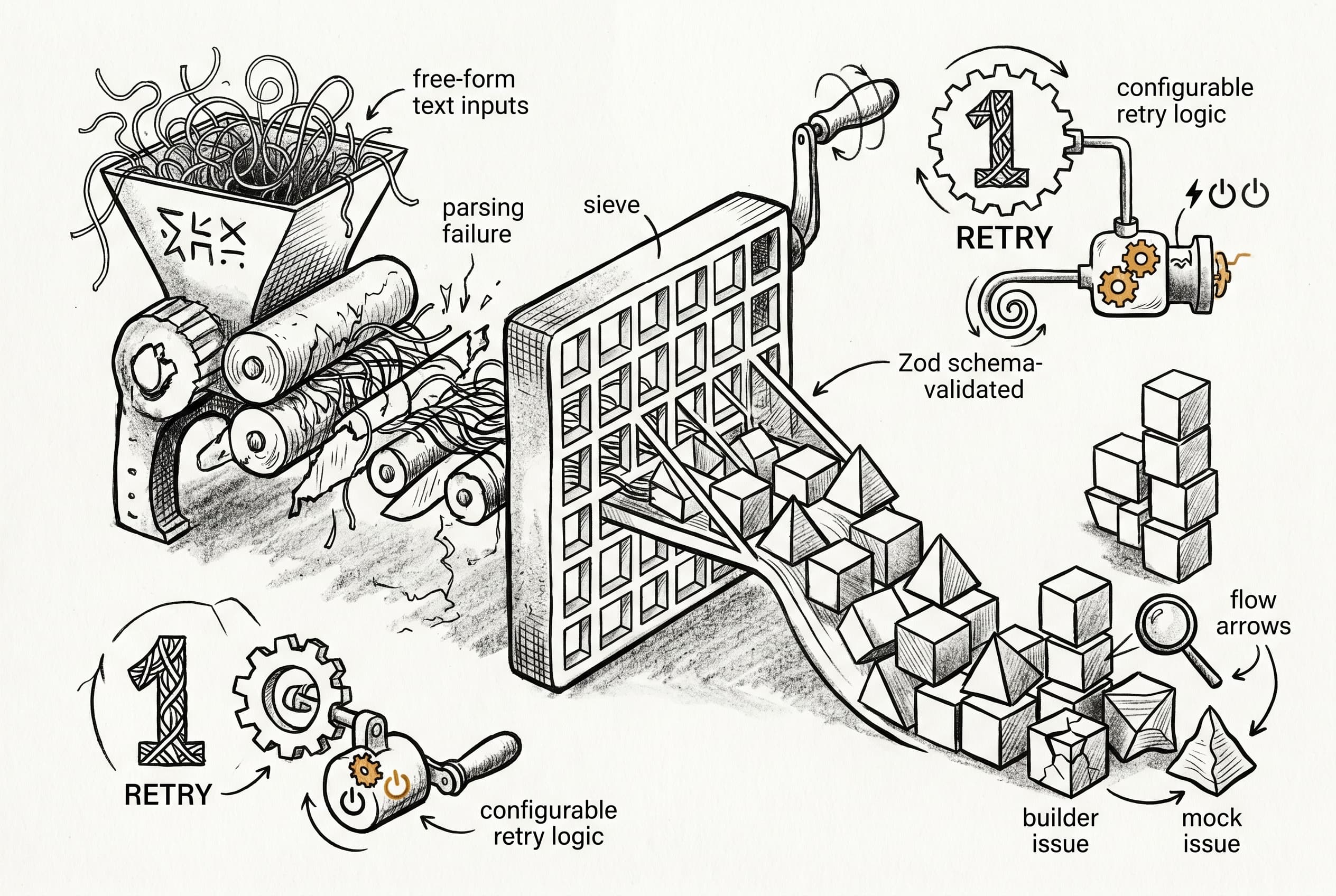
AI evaluation systems now use schema-validated responses instead of parsing free-form text, eliminating the most common cause of verification failures. A retry mechanism for mock handlers adds resilience against transient LLM errors.
When AI builder workflows get tested against evaluation scenarios, the verifier and mock handler are critical infrastructure. Until now, verification results were parsed from free-form text — an approach prone to failure when language models returned non-standard formats. This led to cryptic "No verification result" errors that required manual debugging to resolve.
The verifier now uses structured output with a Zod schema, meaning responses are validated against a defined contract rather than extracted from unstructured text. The mock handler gained configurable retry logic (default: one retry) to recover from transient generation failures. Failure categorization was also improved — the system now traces data flow before attributing problems, correctly distinguishing builder logic errors from mock data issues.
Test scenarios were loosened to avoid brittleness. Success criteria that expected exactly 10 posts or required specific response shapes were made more flexible. The REST API pipeline prompt no longer specifies a hard count, and the GitHub-Notion sync scenario hints at minimal responses rather than expecting complete objects.
These changes live in the instance-ai package and affect evaluation infrastructure for AI builder workflows.
View Original GitHub Description
Summary
- Use structured output on the verifier to eliminate "No verification result" failures — response is now schema-validated instead of parsed from free-form text
- Add retry logic to the mock handler with configurable
maxRetries(default 1) to recover from transient LLM failures - Improve failure categorization — verifier now traces data flow before attributing failures, correctly distinguishing builder logic errors from mock data issues
- Remove hardcoded
maxTokensoverrides, let the AI SDK use model defaults - Make test case scenarios less brittle (remove exact count expectations, use minimal response hints)
Related Linear ticket
https://linear.app/n8n/issue/TRUST-34
Test plan
- Mock handler tests: 32/32 pass
- Typecheck clean (instance-ai)
- Full suite run: zero "No verification result", 1 mock_issue out of 27 scenarios
🤖 Generated with Claude Code