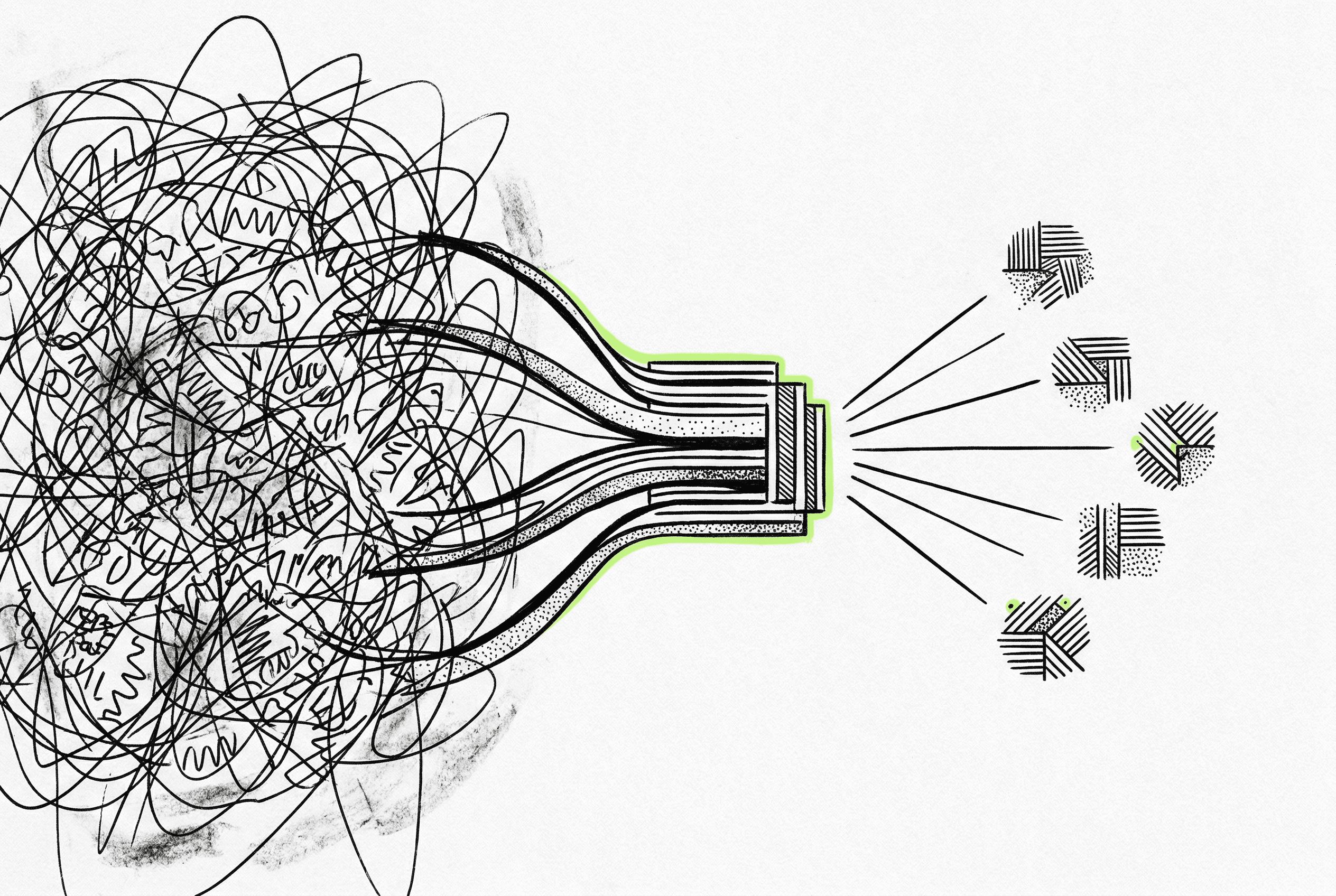
Developers can track recurring failures without sifting through thousands of duplicate logs. A new dashboard aggregates failed executions by extracting the underlying error signature, creating a clean list of unique issues affecting a project.
When an execution crashes, the system analyzes the stack trace and error message, strips out dynamic variables like timestamps, UUIDs, and file paths, and generates a . These fingerprints group identical problems together regardless of the specific data payload that caused them.
Users can click into any grouped error to see plotted over time, identifying exactly when a spike started. From there, they can filter the exact list of affected executions and trigger a bulk replay once the code is patched. Fast load times are maintained by in the analytics database that keep running totals per minute.